Snappy - LLMs Speed Test
• 0 views

AI is becoming really useful, and now you can even run some of these smart AI models right on your own computer. Instead of always needing to use big online services like OpenAI or Anthropic, you can have AI working for you directly on your machine. This is great because it can be faster, more private, and even work when you're offline.
But, there are lots of these "local AI models" out there, and they can be set up in different ways. How do you know which one is actually fast on your computer?
Figuring Out Your Local AI Model Speed
That's where Snappy comes in. It's a web app I made to help you see how fast your local AI model is running. Lots of folks are using tools like Ollama to get these AI models working on their computers. Ollama makes it easier to download and use them.
But here's the thing: just because you have an AI model running doesn't mean it's running well on your computer. Is it fast? Is it slow? How does it compare to another model you could use? It's hard to know! Snappy fixes this. It gives you a simple way to test the speed and see how well your local AI model is performing.
Your Computer's Got Smarts!
It's pretty amazing that we can now run these powerful language models on regular computers. You don't need huge data centers or expensive cloud services anymore. There are lots of free and smaller models you can download and run.
This is awesome for anyone who's curious about AI or wants to build things with it. But, it also means we need a way to check how fast these models are working right on our own machines. Snappy is all about giving you that power - to see the real speed on your hardware.
Easy Tools Make AI Local
Tools like Ollama and LM Studio have made running local AI models much simpler. Ollama is like a command-line tool - you type in commands to manage and run your models. LM Studio is more visual, with buttons and menus, making it even easier to use.

These tools let you try out different models easily. But choosing the best one for your computer, and knowing how fast it will actually be, is still a guess. Snappy jumps in to help here. It gives you a quick way to test the speed of your AI model and see how it performs.
Benchmarking with Snappy: How it Works
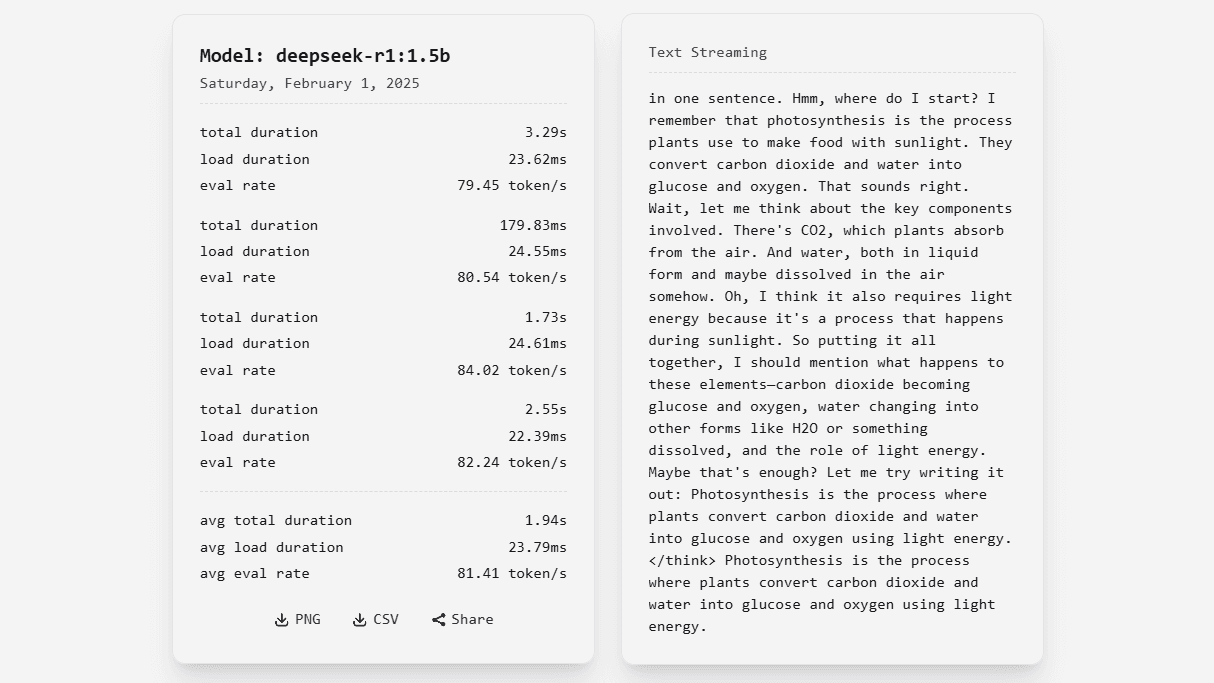
Snappy's testing process is designed to be simple and informative. Currently, Snappy focuses on benchmarking local AI models that you are running through Ollama. Ollama is a popular tool that makes it easy to download and run AI models directly on your computer, and Snappy is built to work seamlessly with it.
To get started, you simply select an AI model that you have already set up and running with Ollama. Then, with just a click, you can run four speed tests to see exactly how fast that model performs on your system.
Looking ahead, I plan to expand Snappy to support even more ways to run AI models. This includes adding support for other local model platforms like LM Studio, giving you even more flexibility in testing local AI.
I also envision a future where Snappy can benchmark models from cloud providers like OpenAI, Anthropic Claude, and others, allowing you to compare performance across different environments - local and cloud - all within one tool. But for now, Snappy starts by making it easy to understand the speed of your Ollama-powered local AI models.
The Tests: Easy to Hard
Snappy uses four tests that get a little harder each time. Think of them like levels in a game!
- Easy Test: This is a quick and simple test. It uses a short question that the model should answer quickly. It's like a warm-up to see the model's base speed.
- Medium Test: This test is a bit longer and more involved. It asks a question that needs a slightly longer answer and a bit more thinking from the model. This shows how the model performs under a bit more load.
- Difficult Test: This is the toughest test. It uses a longer, more complex question that needs a detailed answer. This really pushes the model to work harder and shows you its speed when it's doing more heavy lifting. These different tests help you see how the model's speed changes as you ask it to do more work.
What's a Good Result? Tokens Per Second Explained
After each test, Snappy shows you a number called "tokens/s". Remember, "tokens" are like words. So, "tokens per second" (tokens/s) tells you how many words the AI model can process every second. The higher this number, the faster the model. So, what's a good number?
- Generally, if you see tokens/s above 50-60, that's pretty good. This means the model is likely fast enough for many common tasks, like quickly generating code snippets, writing drafts of text, or answering questions without too much waiting.
- Lower numbers (like 20-40 tokens/s) mean the model is slower. It will still work, but you might notice a delay when you ask it to do things, especially for longer or more complex requests.
- Very low numbers (below 20 tokens/s) might feel quite slow for interactive use.
Keep in mind, "good" speed can depend on what you're doing. If you need quick, back-and-forth conversations with the model, you'll want higher tokens/s. If you're okay with waiting a bit longer for more detailed responses, a slightly lower number might be fine.
The best way to use Snappy is to compare different models on your computer. Even if one model doesn't have a super high tokens/s number, you can still see if it's faster or slower than another model on your own machine. This helps you choose the best model for your needs and hardware.
Real-World Speed Tests: Snappy in Action
To give you a better idea of what Snappy can do, I ran some tests on a common setup: a desktop computer with a NVIDIA 1660s graphics card (6GB of VRAM) and 16GB of RAM. I used Snappy to benchmark a few popular models available through Ollama.
Here are the results I saw:
| # Model | Avg. Total Duration | Avg. Load Duration | Avg. Eval Rate | | ----------------------------------------------------------------- | ------------------- | ------------------ | -------------- | | Deepseek R1 - 1.5b | 3.33s | 27.47ms | 80.25 token/s | | Llama 3.2 - 3b | 369.33ms | 28.77ms | 50.90 token/s | | Qwen 2.5 - 3b | 438.14ms | 27.68ms | 51.00 token/s | | Mistral - 7b | 537.50ms | 13.78ms | 36.19 token/s | | Deepseek R1 - 7b | 7.30s | 31.75ms | 18.62 token/s | | Phi4 - 14b | 14.74s | 43.12ms | 3.83 token/s |
Looking at these results, you can see some interesting things. For example, the smaller models like "Deepseek R1 - 1.5b" are incredibly fast, giving you a very snappy 80 tokens per second! As you move to larger models like "Mistral - 7b" and "Deepseek R1 - 7b," the speed naturally goes down, but they might offer more detailed or complex responses. And you can really see the impact of model size with "Phi4 - 14b," which, while powerful, is significantly slower on this hardware.
This is exactly why Snappy is useful! It lets you quickly see these performance differences for yourself, on your computer, with the models you want to use. No more guessing - just run Snappy and see the numbers!
Wrapping Up: Know Your AI Model Speed
Snappy - LLMs Speed Test is a really useful tool if you're playing with local language models. It takes away the guesswork and gives you a clear way to see how fast they are. This helps you make smart choices about which model is best for what you need and for your computer.
As local AI becomes more common, tools like Snappy are going to be super important. They help everyone - from curious users to developers - get the most out of this exciting new tech. Whether you're just starting out or you're building cool things with AI, Snappy helps you understand and use local AI models to their full potential.